The need for localizing software arises from differences in cultural conventions. These differences involve: language itself; representation of numbers and currency; display of time and date; and ordering and classification of characters and strings.
Of course, language itself varies from country to country, and even within a country. Your program may require output messages in English, Deutsche, Français, Italiano, or any number of languages commonly used in the world today.
Languages may also differ in the alphabet they use. Examples of different languages with their respective alphabets are given below:
American English: | a-z, A-Z, and punctuation |
German: | a-z, A-Z, punctuation, and äöü ÄöÜ ß |
Greek: |
|
The representation of numbers depends on local customs, which vary from country to country. For example, consider the radix character, the symbol used to separate the integer portion of a number from the fractional portion. In American English, this character is a period; in much of Europe, it is a comma. Conversely, the thousands separator that separates numbers larger than three digits is a comma in American English, and a period in much of Europe.
The convention for grouping digits also varies. In American English, digits are grouped by threes, but there are many other possibilities. In the example below, the same number is written as it would be locally in three different countries:
1,000,000.55 | US |
1.000.000,55 | Germany |
10,00,000.55 | Nepal |
We are all aware that countries use different currencies. However, not everyone realizes the many different ways we can represent units of currency. For example, the symbol for a currency can vary. Here are two different ways of representing the same amount in US dollars:
$24.99 | US |
USD 24.99 | International currency symbol for the US |
The placement of the currency symbol varies for different currencies, too, appearing before, after, or even within the numeric value:
¥ 155 | Japan |
13,50 DM | Germany |
£14 19s. 6d. | England before decimalization |
The format of negative currency values differs:
öS 1,1 | -öS 1,1 | Austria |
1,1 DM | -1,1 DM | Germany |
SFr. 1.1 | SFr.-1.1 | Switzerland |
HK$1.1 | (HK$1.1) | Hong Kong |
Local conventions also determine how time and date are displayed. Some countries use a 24-hour clock; others use a 12-hour clock. Names and abbreviations for days of the week and months of the year vary by language.
Customs dictate the ordering of the year, month, and day, as well as the separating delimiters for their numeric representation. To designate years, some regions use seasonal, astronomical, or historical criteria, instead of the Western Gregorian calendar system. For example, the official Japanese calendar is based on the year of reign of the current Emperor.
The following example shows short and long representations of the same date in different countries:
10/29/96 | Tuesday, October 29, 1996 | US |
1996. 10. 29. | 1996. október 29. | Hungary |
29/10/96 | martedì 29 ottobre 1996 | Italy |
29/10/1996 |
| Greece |
29.10.96 | Dienstag, 29. Oktober 1996 | Germany |
The following example shows different representations of the same time:
4:55 pm | US time |
16:55 Uhr | German time |
And the following example shows different representations of the same time:
11:45:15 | Digital representation, US |
11:45:15 µµ | Digital representation, Greece |
Languages may vary regarding collating sequence; that is, their rules for ordering or sorting characters or strings. The following example compares the same list of words ordered alphabetically by different collating sequences:
Sorted by ASCII rules: | Sorted by German rules: |
Airplane | Airplane |
Zebra | ähnlich |
bird | bird |
car | car |
ähnlich | Zebra |
The ASCII collation orders elements according to the numeric value of bytes, which does not meet the requirements of English language dictionary sorting. This is because lexicographical order sorts a after A and before B, whereas ASCII-based order sorts a after the entire set of uppercase letters.
The German alphabet sorts ä before b, whereas the ASCII order sorts an umlaut after all other letters.
In addition to specifying the ordering of individual characters, some languages specify that certain groups of characters should be clustered and treated as a single character. The following example shows the difference this can make in an ordering:
Sorted by ASCII rules: | Sorted by Spanish rules: |
chaleco | cuna |
cuna | chaleco |
día | día |
llava | loro |
loro | llava |
maíz | maíz |
The word llava is sorted after loro and before maíz, because in Spanish ll is a digraph, i.e., it is treated as a single character that is sorted after l and before m. Similarly, the digraph ch in Spanish is treated as a single character to be sorted after c, but before d. Two characters that are paired and treated as a single character are referred to as a two-to-one character code pair.
In other cases, one character is treated as if it were actually two characters. The German single character ß, called the sharp s, is treated as ss. This treatment makes a difference in the ordering, as shown in the example below:
Sorted by ASCII rules: | Sorted by German rules: |
Rosselenker | Rosselenker |
Rostbratwurst | Roßhaar |
Roßhaar | Rostbratwurst |
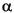 -
-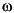 ,
, 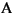 -
-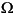 , and punctuation
, and punctuation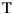
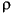
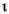
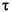
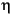 , 29
, 29 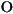
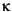
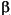
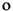
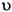 1996
1996